Giới thiệu về ứng dụng đàm thoại
Ngày nay, hàng tháng các trợ lý ảo như Siri, Cortana, Google Assistant và Alexa đã đưa ra hàng tỷ câu tư vấn bằng giọng nói và ngôn ngữ tự nhiên. Người dùng trên toàn thế giới ngày càng mong muốn sự trợ giúp nhanh chóng và tư vấn chuyên môn chỉ thông qua một lệnh thoại đơn giản hoặc một cuộc trò chuyện ngắn. Điều đó dẫn tới sự nổi lên của giao diện đàm thoại.
Trong vài năm gần đây, phương pháp tiếp cận học máy, đó là học tập có giám sát và học sâu (deep learning), đã chứng minh hiệu quả trong việc hiểu ngôn ngữ tự nhiên trong một phạm vi rộng các từ vựng. Cho đến nay, học máy có giám sát quy mô lớn là cách tiếp cận duy nhất để tạo ra các ứng dụng đàm thoại hữu ích thực sự được hàng triệu người dùng chấp nhận. Tất cả các dịch vụ đàm thoại được sử dụng rộng rãi nhất hiện nay như Cortana, Siri, Google Assistant và Alexa đều dựa vào việc học có giám sát quy mô lớn. Hai thành phần chính của hệ thống học tập được giám sát là dữ liệu đào tạo chất lượng cao và các thuật toán hiện đại. Dữ liệu huấn luyện phản ánh phạm vi đầu vào của người sử dụng và đưa ra những kinh nghiệm ứng dụng trong quá trình sử dụng thông thường. Các thuật toán học cách nhận ra các mẫu quan trọng trong dữ liệu thỏa mãn yêu cầu.
Đối với việc học có giám sát, bất kỳ ứng dụng nào cũng chỉ thông minh như các dữ liệu cơ bản của tập huấn luyện. Công nghệ học máy ngày nay không có khả năng thể hiện trí thông minh chưa được phản ánh trong dữ liệu đào tạo của nó. Để xây dựng một ứng dụng đàm thoại hữu ích, trước tiên phải đi vào thực tế để thu thập dữ liệu đào tạo mà minh hoạ một cách toàn diện hành vi sử dụng mong muốn. Đối với các ứng dụng mà dữ liệu huấn luyện đại diện phong phú, các kỹ thuật mạng nơ-ron học sâu có thể mang lại kết quả ấn tượng. Đối với các ứng dụng với số lượng dữ liệu khiêm tốn, chúng ta sử dụng các kỹ thuật máy học thông thường để cung cấp xác suất chấp nhận được. Chúng ta cần xây dựng cho AI các miền kiến thức (domain). Mỗi miền có một tập dữ liệu huấn luyện riêng.
Các cách tiếp cận khác nhau cho việc xây dựng các ứng dụng đàm thoại
Các nhà phát triển / nghiên cứu đã xây dựng các ứng dụng trò chuyện, ví dụ như chatbot trong nhiều năm, nhiều chiến lược khác nhau đã được xem xét. Dưới đây là một số các chiến lược xây dựng ứng dụng chatbot:
Tiếp cận dựa trên nguyên tắc
Trước khi có những tiến bộ về trí tuệ nhân tạo, các ứng dụng đàm thoại thường được xây dựng dựa trên các quy tắc (rule-based). nhà phát triển không quen với việc học máy thường bắt đầu triển khai bằng logic dựa trên quy tắc. Ngày nay, một số framework dựa trên quy tắc, chẳng hạn như BotKit hoặc Microsoft Bot Framework có thể giúp người phát triển có được các dịch vụ đàm thoại đơn giản. Các framework cung cấp một core logic xử lý messages và hệ thống pipeline để tích hợp với các endpoint khác nhau của máy client. Họ đơn giản hóa quá trình thiết lập một máy chủ để lắng nghe các tin nhắn văn bản đến và sắp xếp các interfaces để tích hợp với các client phổ biến như Slack hoặc Facebook Messenger.
Với các framework dựa trên quy tắc, nhà phát triển có trách nhiệm thực hiện core logic để hiểu các message đến và trả lời phản hồi. Logic này thường bao gồm một loạt các quy tắc chỉ định đáp ứng kịch bản: sẽ phản hồi một thông báo phù hợp với một mẫu được chỉ định. Vì các framework dựa trên quy tắc không cung cấp khả năng AI để phân tích cú pháp hoặc phân loại các messages nên nhà phát triển phải mã hoá tất cả các logic xử lý và giao tiếp cần thiết một cách manual. Ngay cả những ứng dụng đơn giản cũng đòi hỏi hàng trăm quy tắc để xử lý các trạng thái đối thoại khác nhau trong một giao diện truyền thống.
Cách tiếp cận dựa trên quy tắc thường là cách nhanh nhất để xây dựng và khởi chạy một bản demo cơ bản về trợ lý, chatbot. Tuy nhiên khi chuyển từ phiên bản demo sang bản production hầu như luôn luôn có vô số các trường hợp ngoại lệ, mỗi trường hợp phải được xử lý với các quy tắc khác nhau. Xung đột và sự dư thừa giữa các quy tắc làm phức tạp hơn nữa các ràng buộc logic. Ngay cả đối với các ứng dụng đơn giản, danh sách các tập quy tắc có thể nhanh chóng trở nên phức tạp.
Vì vậy nhà phát triển ứng dụng thường lựa chọn những cách dưới đây thay cho cách phát triển dựa trên nguyên tắc:
Dịch vụ Nature Language Processing (NLP) trên đám mây
Trong vài năm gần đây, một loạt các dịch vụ xử lý ngôn ngữ tự nhiên dựa trên đám mây (NLP) đã nổi lên, mong muốn làm giảm sự phức tạp liên quan đến việc xây dựng các phần mềm có khả năng hiểu ngôn ngữ. Các dịch vụ này nhằm giúp nhà phát triển không cần phải biết về học máy hoặc chuyên môn về xử lý ngôn ngữ tự nhiên để tạo ra các ứng dụng đàm thoại hữu ích. Tất cả các dịch vụ này cung cấp giao diện điều khiển dựa trên trình duyệt giúp các nhà phát triển tải lên và chú thích các ví dụ đào tạo. Họ cũng thiết kế các dịch vụ web dựa trên đám mây để xử lý và phân tích các yêu cầu ngôn ngữ tự nhiên. Các dịch vụ này thường được cung cấp bởi các công ty Internet lớn để thu hút các nhà phát triển tải lên dữ liệu huấn luyện của họ và do đó giúp nhà cung cấp dịch vụ cải tiến các dịch vụ AI truyền thống của họ trong quá trình này. Trong số các dịch vụ NLP hiện có là Amazon Lex, api.ai của Google, Facebook's wit.ai, Microsoft LUIS, Viv của Samsung và IBM Watson Conversation.
Các dịch vụ NLP dựa trên đám mây cung cấp các phương thức tương đối đơn giản cho các nhà phát triển để xây dựng các ứng dụng đàm thoại mà không cần kiến thức về máy học. Do đó, chúng có thể là con đường nhanh nhất để code một bản giới thiệu hoặc mẫu thử nghiệm. Cloud cung cấp các mô hình được đào tạo trước cho các tác vụ phổ biến của người tiêu dùng như kiểm tra thời tiết, cài đặt báo thức hoặc hẹn giờ, cập nhật danh sách việc cần làm hoặc gửi tin nhắn văn bản. Điều này phù hợp với các ứng dụng đơn giản chỉ cần sao chép các domain thông thường mà không cần tuỳ biến.
Đối với các công ty cần xây dựng một ứng dụng phức tạp, vượt xa một bản giới thiệu đơn giản và yêu cầu các mô hình khác với lĩnh vực người dùng đã được đào tạo trước, các dịch vụ NLP dựa trên đám mây thường không phải là cách tiếp cận tốt nhất. Xây dựng các mô hình hiểu biết ngôn ngữ phù hợp với một ứng dụng hoặc miền cụ thể đòi hỏi phải đào tạo các mô hình trên hàng ngàn hoặc hàng triệu ví dụ về dữ liệu đào tạo. Các dịch vụ NLP dựa trên đám mây thường nhắm vào các nhà phát triển là những người không có nhiều dữ liệu đào tạo nên họ thường dùng cho các bộ dữ liệu nhỏ hơn và các mô hình tùy chỉnh đơn giản hơn. Ngoài ra, hầu hết các dịch vụ NLP dựa trên đám mây chỉ hỗ trợ các tác vụ NLP cơ bản như phân loại mục đích (intent) và sự thừa nhận thực thể (entity). Nhà phát triển sẽ phải thực hiện các bước xử lý yêu cầu khác chẳng hạn như độ phân giải thực thể, phân tích ngôn ngữ, trả lời câu hỏi và tạo cơ sở kiến thức ... Có lẽ quan trọng nhất đối với các công ty là không thể hoặc không muốn từ bỏ quyền sở hữu hợp pháp của dữ liệu người dùng khi nó được tải lên đám mây của nhà cung cấp dịch vụ.
Vì vậy hãng mindmeld muốn cung cấp một framework riêng để nhà phát triển có thể tự xây dựng, training kiến thức cho AI để chuyên xây dựng ứng dụng đàm thoại. Framework này có đủ các tính năng cần thiết để xây dựng mô hình đàm thoại, phân loại được intent và entity của người dùng, đưa dữ liệu training và chọn thuật toán deeplearning để AI có thể học và nâng cao khả năng trả lời câu hỏi. Dữ liệu training như vậy sẽ không cần phải public lên dịch vụ của một hãng thứ 3.
Tuy vậy mindmeld không public framework này mà chỉ đưa ra ebook thuyết minh về cách làm để xây dựng một ứng dụng đàm thoại. Trong thời gian có hạn của môn học, nhóm mới tập trung vào cách thức xây dựng đàm thoại sử dụng dịch vụ đám mây của IBM watson. Phần việc nghiên cứu về deeplearning và cách thức xây dựng framework tương tự như mindmeld nhóm mới dừng lại ở mức nghiên cứu và sẽ trình bày ở phần cuối
Cấu trúc của một ứng dụng đàm thoại

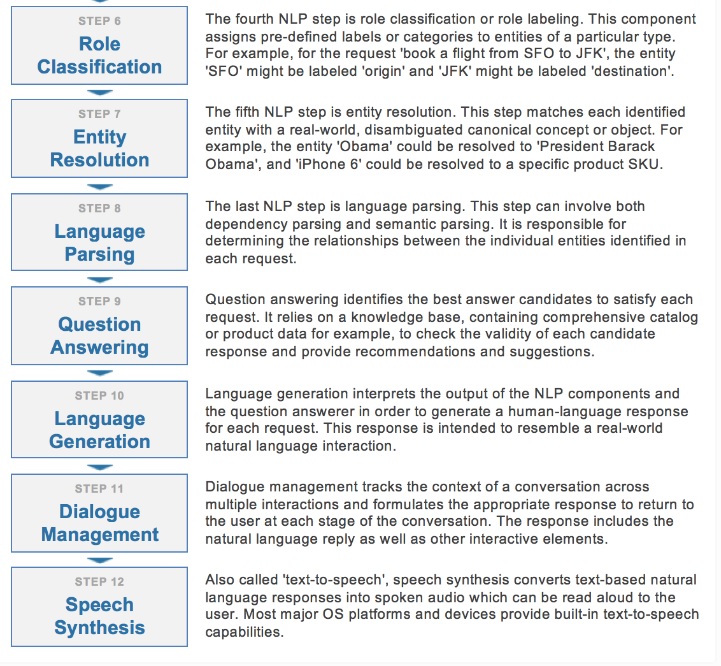
Xây dựng một giao diện đàm thoại trong 10 bước
Lấy một ứng dụng đàm thoại từ lúc bắt đầu đến sản xuất thường đòi hỏi phải hoàn thành mười bước thực hiện tóm tắt dưới đây.
| 1 | Chọn trường hợp sử dụng đúng |
|---|---|
| 2 | Scripts tương tác đoạn đối thoại lý tưởng |
| 3 | Xác định lĩnh vực, ý định, tổ chức , và phân cấp vai trò của hệ thống |
| 4 | Xác định dialog và các trạng thái của cuộc đối thoại |
| 5 | Tạo câu hỏi , câu trả lời kiến thức cơ bản |
| 6 | Tạo dữ liệu đào tạo đại diện |
| 7 | Đào tạo phân loại xử lý ngôn ngữ tự nhiên |
| 8 | Thực hiện phân tích cú pháp ngôn ngữ |
| 9 | Tối ưu hóa hiệu suất trả lời câu hỏi |
| 10 | Triển khai mô hình đào tạo trên môi trường production |
Lựa chọn trường hợp sử dụng đúng có lẽ là bước quan trọng nhất trong việc xây dựng một ứng dụng đàm thoại .Đối với nhiều trường hợp sử dụng, một ra lệnh bằng giọng nói hoặc trò chuyện hội thoại làm đơn giản cách tìm thông tin hoặc thực hiện một nhiệm vụ. Đối với nhiều trường hợp khác, một giao diện đàm thoại có thể bất tiện.Lựa chọn một trường hợp sử dụng không thực tế hoặc không chính xác sẽ làm cho ứng dụng không hiệu quả để sử dụng.
Trong khi không có công thức chung để xác định trường hợp nào là lý tưởng cho một giao diện đàm thoại, một số thực nghiệm đã bắt đầu xuất hiện để phân biệt các trường hợp tốt / xấu để đảm bảo rằng ứng dụng đàm thoại có thể xây dựng và cung cấp giá trị thực sự cho người sử dụng. Đây là một số câu hỏi để xác định ứng dụng đàm thoại có phù hợp hơn ứng dụng truyền thống hay không:
| Ứng dụng có giống như một con người tương tác trong thực tế? | giao diện đàm thoại không đi kèm với hướng dẫn sử dụng, và có rất ít cơ hội để dạy cho người dùng về các chức năng hỗ trợ.Các trường hợp sử dụng tốt nhất bắt chước một tình huống hiện có, quen thuộc để người dùng biết những gì họ có thể yêu cầu và làm thế nào các dịch vụ có thể giúp đỡ NSD. Ví dụ, một giao diện đàm thoại có thể bắt chước một sự tương tác với một nhân viên giao dịch ngân hàng, hoặc một đại diện hỗ trợ khách hàng. |
|---|---|
| Liệu người dùng có tiết kiệm thời gian? | giao diện đàm thoại tốt khi tiết kiệm thời gian người sử dụng. Giao diện đàm thoại được xem như một trở ngại khi một giao diện thông thường được thiết kế tốt sẽ nhanh hơn.Những kinh nghiệm đàm thoại hữu ích nhất thường tập trung xung quanh những trường hợp mà người dùng đang tìm kiếm để thực hiện một nhiệm vụ cụ thể và biết làm thế nào để nói lên điều đó.Ví dụ, chỉ cần nói 'chơi playlist smooth jazz của tôi trong nhà bếp' có thể nhanh hơn nhiều so với popup một ứng dụng và điều hướng đến các tùy chọn tương đương bằng cảm ứng. |
| Thuận tiện hơn cho người sử dụng? | giao diện giọng nói có thể đặc biệt hữu ích khi bàn tay và sự chú ý của người sử dụng đang chú ý vào việc khác hoặc không có thiết bị di động trong tầm tay.Nên làm ứng dụng đàm thoại để sử dụng trong khi lái xe, đi xe đạp, đi bộ, tập thể dục, nấu ăn... |
| Ứng dụng có rơi vào vùng phù hợp để chuyển sang giao diện đàm thoại? | Các ứng dụng đàm thoại tốt nhất rơi thẳng vào 'vùng Goldilocks.' (vùng phù hợp) Phạm vi của các chức năng mà họ cung cấp vừa đủ hẹp để đảm bảo rằng các mô hình học máy đạt độ chính xác cao, và rộng đủ để người dùng tìm thấy những kinh nghiệm hữu ích cho một loạt các nhiệm vụ.Ứng dụng đang quá hẹp có thể tầm thường và vô dụng.Ứng dụng quá rộng có thể không quản lý nổi các câu hỏi của người sử dụng. |
| Có thể để có được đủ dữ liệu đào tạo? | Ngay cả những trường hợp sử dụng tốt nhất thất bại khi không thể thu thập đủ dữ liệu huấn luyện để phản ánh đầy đủ các chức năng hình dung.Đối với trường hợp sử dụng lý tưởng, dữ liệu huấn luyện có thể dễ dàng tạo ra từ môi trường production hoặc kỹ thuật crowdsourcing. Nếu dữ liệu đào tạo đối với trường hợp sử dụng của bạn quá ít sẽ không phù hợp cho giao diện đàm thoại. |
Ứng dụng Điều khiển xe ô tô
Ứng dụng điền khiển xe ô tô sử dụng IBM watson conversation là một dịch vụ của cloud IBM Bluemix. Nhìn chung phần lý thuyết của MindMeld trùng khớp với dịch vụ của IBM watson conversation. Cụ thể như sau:
Dịch vụ của IBM có sẵn một AI (watson). AI này được tranning một số miền kiến thức (domain) có sẵn như weather, fly, cars, alarm... gọi là prebuilt agents. AI cũng có bộ xử lý ngôn ngữ tự nhiên support khoảng 14 ngôn ngữ. Điểm cơ bản của dịch vụ IBM watson là cung cấp cách thức để người dùng xây dựng kịch bản cho Conversation Apps. Ví dụ khi xây dựng ứng dụng đàm thoại trên xe ô tô, chúng ta sẽ không huấn luyện cho AI về chủ đề bán hàng hay hỏi về lịch bay mà chỉ tập trung vào 1 số chủ đề như: ra lệnh cho xe tắt/bật đèn, hỏi về thời tiết, hoặc ra lệnh cho xe chơi nhạc. Nâng cấp hơn 1 chút thì AI có thể trả lời 1 số câu hỏi về hướng dẫn sử dụng xe, ví dụ như: làm thế nào để kiểm tra áp suất lốp? Làm thế nào để đi xe tiết kiệm xăng? ...
Để giải quyết bài toán như vậy, IBM chia làm 2 loại services: conversation và discovery.
Conversation giúp người phát triển xây dựng kịch bản của cuộc hội thoại. Người phát triển tự định nghĩa ra các intent của chương trình. Intent chính là ý định của người sử dụng. Mục đích cuối cùng của cuộc hội thoại là tìm ra Intent của NSD.
Ví dụ: NPT định nghĩa intent: @turn__on với danh sách khoảng 100 câu nói: turn on the light, turn on my phone ... Khi gặp những câu nói này, thì AI nhận diện đó là intent @turn__on
Đây là định nghĩa intent turn on + các câu hội thoại được nhận diện là intent @turn_on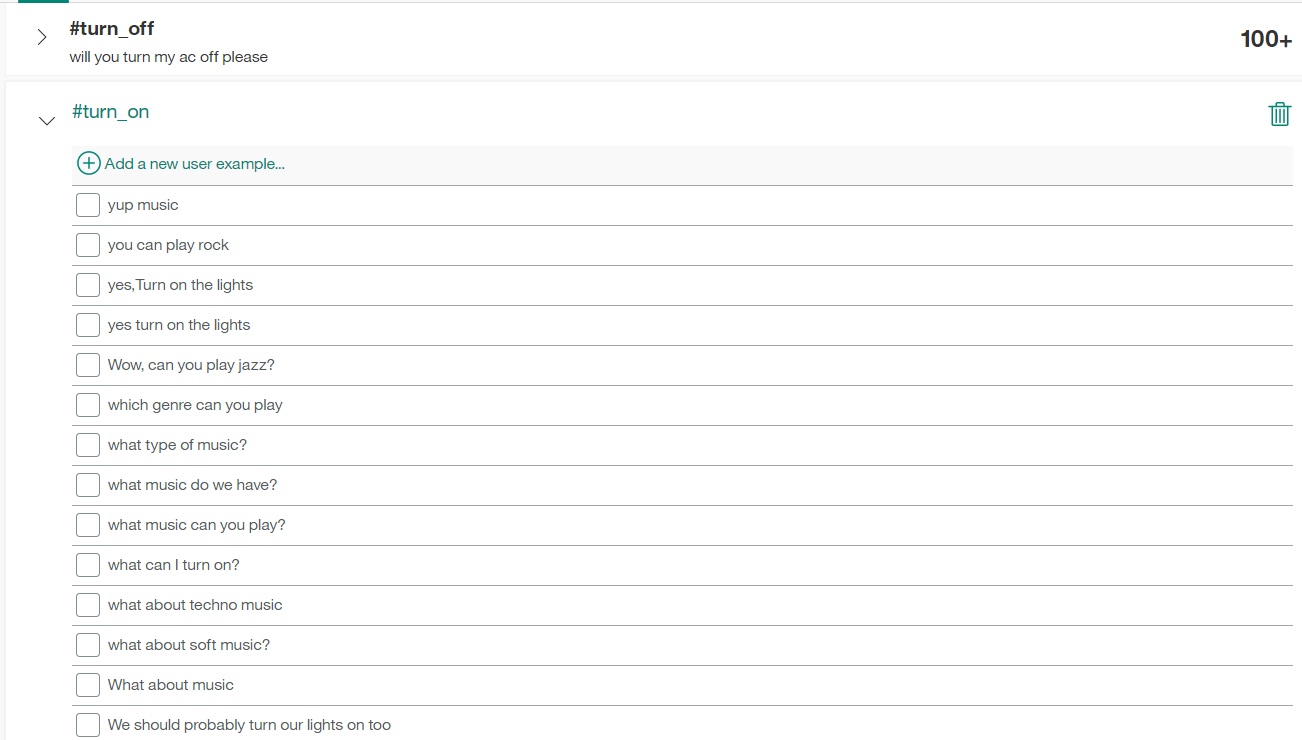
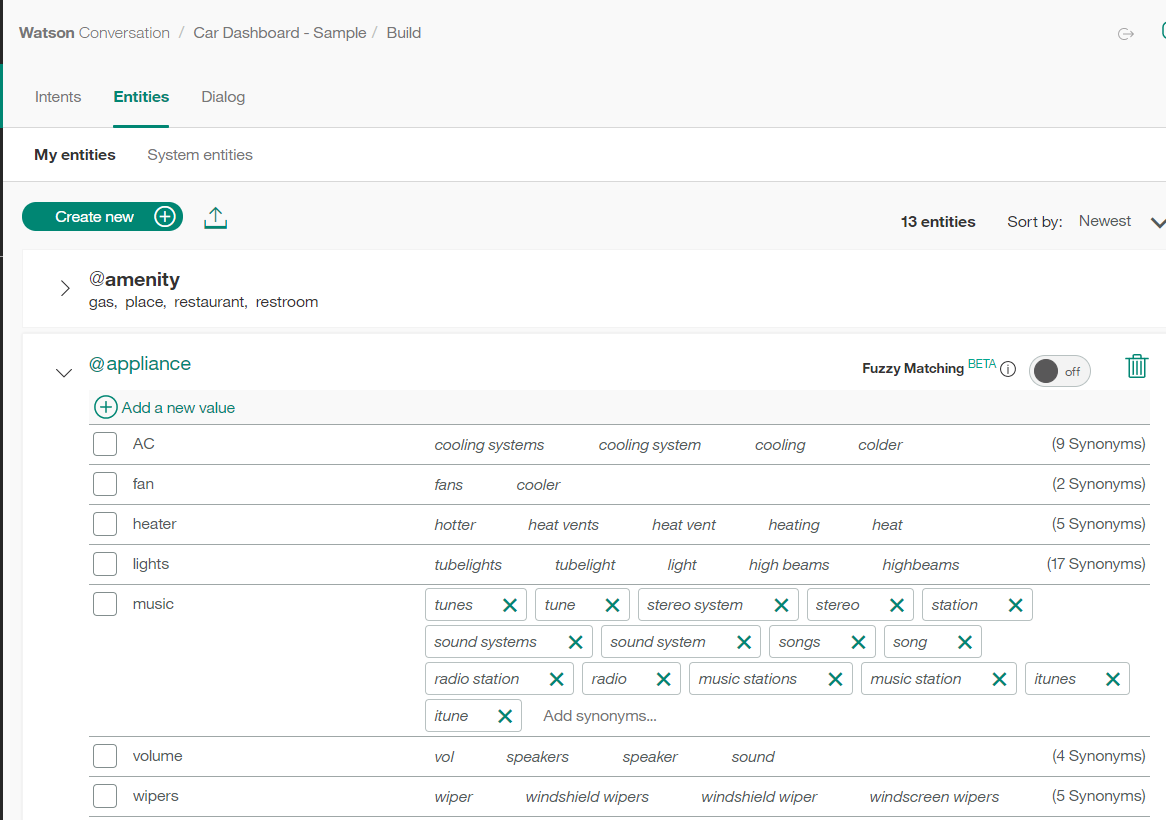
Ngoài Intent, NPT còn phải định nghĩa @Entity. Entity là thực thể trong câu nói, ví dụ: Turn on the light, thì ta phải định nghĩa một Entity là @Appliance. Trong entity @Appliance ta định nghĩa cặp key value: key: light, value: light, fog light, head light, tube light ...
Như vậy khi gặp câu có từ head light thì AI hiểu đó tương đương với @Appliance:light . Cách đánh dấu thực thể này để phục vụ thiết kế kịch bản của cuộc hội thoại. Bây giờ ta sẽ đi vào cách thiết kế cuộc hội thoại để phục vụ viết một Conversation Apps.
Để viết 1 Conversaction Apps thì bắt buộc phải có 1 ô dialog để người phát triển thiết kế và kiểm thử cuộc trò chuyện. IBM cung cấp giao diện để ta thiết kế cuộc hội thoại. Ví dụ 1 cuộc hội thoại đơn giản: NSD muốn bật/ tắt các thiết bị trên xe, hoặc chơi nhạc. NSD có thể ra lệnh: turn on the radio, turn on the head light...
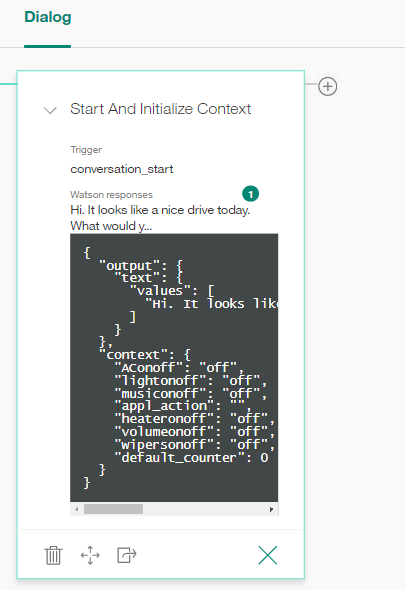
IBM cũng cho phép ta định nghĩa các biến trong dialog để lưu giữ trạng thái của cuộc trò chuyện. Ví dụ khi ta nói: Turn the light on thì cần đặt 1 biến LightOn=true; nếu ta tiếp tục ra lệnh Turn the light on, hệ thống sẽ thông báo: The light already on.
Đây là giao diện Dialog thiết kế cuộc trò chuyện, Start And Intialize Context là node bắt đầu của cuộc trò chuyện.
Đây là giao diện để khai báo các entities.
Đây là giao diện Dialog của ứng dụng điều khiển xe ô tô. Phần điều khiển bật tắt đèn.
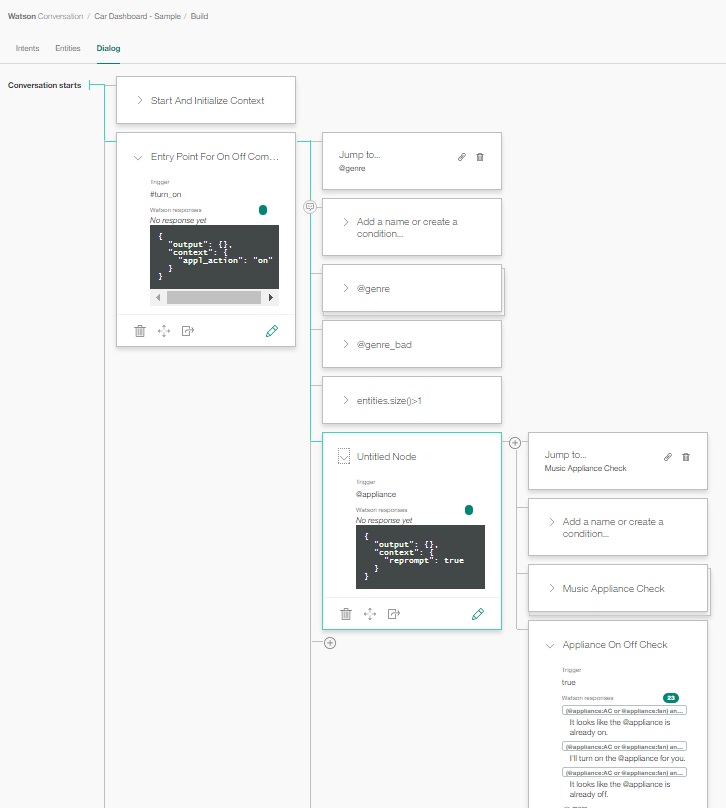
Khi bắt đầu vào ứng dụng, người sử dụng gõ: Turn on the light, ở đây Watson nhận ra Turn on ứng với intent @turn_on. và the light ứng với Entity @Appliance. Chúng ta định nghĩa 1 action Jump to, khi gặp đúng case này sẽ Jump đến node Application On Off Check. Ở đây chúng ta check các biến xem đèn có đang được bật không. Nếu đã bật sẽ trả lời lại It look like the @appliance is already on/off. Đây là 1 case hội thoại đơn giản. Chúng ta có thể định nghĩa nhiều case hội thoại khác phức tạp thì số lượng node/jump to sẽ nhiều hơn.
Watson sẽ trả về kết quả qua Restful API. Ví dụ khi gõ câu Turn on the light thì ta sẽ nhận được response xác định Intent @Turn_on với confidence 99% và câu trả lời mà ta định nghĩa sẵn trong Dialog.
Khi cuộc trò chuyện ra ngoài những intent mà chúng ta cài đặt, watson sẽ trả về câu phản hồi: cuộc nói chuyện ra ngoài phạm vi mà watson hiểu được. Khi đó muốn nâng cao khả năng trả lời của AI, chúng ta sử dụng thêm 1 dịch vụ nữa là dịch vụ discovery của watson. Dịch vụ này cho phép AI thành 1 hệ tư vấn, ví dụ nếu chúng ta đưa vào tập huấn luyện bảng hướng dẫn sử dụng của chiếc xe, thì AI có thể trả lời thêm những câu hỏi, ví dụ: làm thế nào để đi xe tiết kiệm xăng hơn?
Cách dùng dịch vụ discovery cũng đơn giản và tương tự như dịch vụ Conversation, vì thế nhóm không đưa thêm vào báo cáo. Khi thiết kế chương trình ta thường thiết kế để dịch vụ Conversation đón message của người dùng, nếu câu hỏi out of scopes, ta sẽ forward tiếp câu hỏi đến dịch vụ discovery.
Như vậy mô hình làm conversation apps là kết hợp application thông thường với một server cloud của IBM. Ta sẽ định nghĩa kịch bản cuộc trò chuyện ở phía server, và kết nối từ application với cloud bằng web services.
Cách làm này cho phép NPT nhanh chóng có được một ứng dụng chấp nhận được. Tuy vậy nó vẫn còn những hạn chế mà đã nói ở trên, ví dụ như việc huấn luyện AI thì dữ liệu phải upload lên cloud của một third party.
Hướng nghiên cứu tiếp
Để xây dựng được 1 ứng dụng đàm thoại, rõ ràng ta cần thiết kế một framework tương tự như mindmeld hoặc IBM watson conversation nhưng có thể deployment được ở local. Nếu chúng ta chỉ sử dụng IBM hoặc API.AI của google thì sẽ bị hạn chế, tuy nhiên nếu chúng ta chỉ training những framework AI như Tensor Flow và công nghệ Seq2Seq thì sẽ có những khuyết điểm sau:
Một là nếu lượng dữ liệu training thấp, chúng ta sẽ nhận được câu trả lời có độ chính xác rất thấp, ví dụ dưới 10% câu trả lời đúng. Xác suất như vậy khó có thể đưa vào phần mềm thực tế.
Hai là chúng ta chưa xác định được làm thế nào để AI nhận ra intent và entity của người dùng và trả về response cho ứng dụng
Ba là dữ liệu training chưa được lấy online mà vẫn phải dựa vào tập dữ liệu có sẵn. Nếu dựa vào tập có sẵn (ví dụ như lời thoại của film) thì chỉ training được 1 chatbot , không thể training được 1 AI có thể nói chuyện để tìm ra intent của người sử dụng.
Vì những lý do nêu trên nên nhóm mới dừng lại ở việc sử dụng IBM watson. Phần việc tiếp theo nhóm sẽ nghiên cứu các framework AI có khả năng tích hợp như Deeplearning4j, lý thuyết về mạng neuron và deeplearning, supervisor learning, cross validation + realtime learning... để cố gắng xây dựng 1 framework mô phỏng tính năng của Mindmeld.
Website của IBM watson:
https://www.ibm.com/watson/developercloud/doc/conversation/index.html